

0. 简介
之前我们在之前的博客中说了很多关于如何通过帧与地图匹配完成重定位,从而完成位置识别的。同时也有一篇专门用于介绍重定位的博客《定位解析与思考》。目前基于LiDAR的位置识别方法通常是基于无序点或距离像等点云的表示。这些方法实现了很高的检索召回率,但在视图变化或场景变化的情况下,它们的性能可能会下降。而《BEVPlace: Learning LiDAR-based Place Recognition using Bird’s Eye View Images》 这项工作中,我们探索了一种不同的表征在位置识别中的潜力,即鸟瞰(BEV)图像。我们观察到,BEV图像的结构内容受点云的旋转和平移的影响较小。目前这篇论文的代码也已经在Github上开源
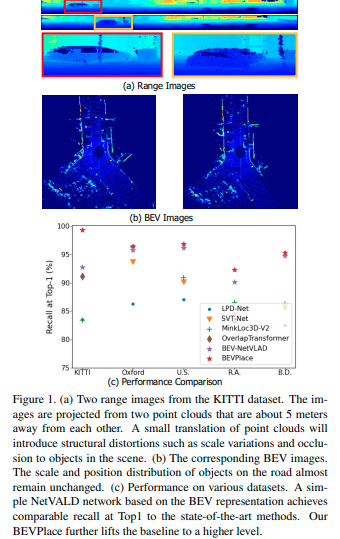
图1. (a)来自KITTI数据集的两个距离图像。这些图像是从相距约5米的两个点云中投影出来的。点云的微小平移将会引入结构失真,如尺度变化和场景中物体的遮挡。(b)对应的BEV图像。道路上物体的尺度和位置分布几乎保持不变。©在各种数据集上的性能。基于BEV表示的简单NetVALD网络在Top1处的召回率与最先进方法相当。我们的BEVPlace进一步提高了基线的水平。
1. 主要贡献
本文贡献如下:
-
提出了一种新的基于LiDAR的位置识别方法BEVPlace。在该方法中,我们基于分组卷积从Bev图像中提取旋转等变的局部特征,这为旋转不变的全局特征的设计提供了便利。
-
探讨了点云对的特征距离和几何距离之间的统计相关性。基于这种相关性先验,我们计算了查询点云和匹配点云之间的几何距离,并将其用于位置估计。
-
我们在三个大规模公共数据集上对我们的方法进行了评估,结果表明,我们的方法对视图变化具有健壮性,具有很强的泛化能力,并且在召回率方面达到了最好的性能。
2. 初步准备工作 (解释概念)
设m_i为传感器在位姿T_i =(R_i,t_i)处收集的点云,其中R_i是旋转矩阵,t_i是位置。由n个点云及其相关位姿形成的数据库可以表示为M = {(m_i,T_i)}_{i = 1,2,…,n}。给定一个查询点云m_q,场所识别旨在从预先构建的数据库M中找到其最具结构相似性的点云。在基于LiDAR的场所识别问题中,通常认为如果两个点云在几何上接近,则它们结构上相似。为了实现这个目标,我们设计了一个网络f(·)将点云映射到一个独特的紧凑全局特征向量,使得如果m_q在结构上类似于m_i但与m_j不相似,则||f(m_q)-f(m_i)||^2 <||f(m_q)-f(m_j)||^2。基于网络f,我们通过找到与查询点云的特征距离最小的点云来执行场所检索。
在这项工作中,我们基于点云的BEV图像训练我们的网络。除了场所检索外,我们还开发了一种扩展用途,用于估计查询点云的位置。
3. 方法总述
文中的方法由两个模块组成,如图2所示。在BEVPlace网络中,我们将查询点云投影到BEV图像中。然后,我们通过一组卷积网络和NetVLAD [2]提取旋转不变的全局特征。在位置估计器中,我们从预先构建的数据库中检索全局特征的最接近特征。我们基于一个映射模型恢复查询和匹配点云之间的几何距离。基于恢复的距离,估计查询的位置。

图2: 我们方法的两个模块。在BEVPlace网络中,我们将点云投影到BEV图像中,并提取旋转不变的全局特征。在位置估计器模块中,我们从特征空间中恢复几何距离,并估计查询点云的位置。
4. BEVPlace网络(重要部分)
在道路场景中,汽车或机器人上的LiDAR传感器只能在地面平面上移动。由于我们通过将点云投影到地面平面上生成BEV图像,因此传感器的视角变化将导致图像上的旋转变换。为了实现稳健的场所识别,我们旨在设计一个网络f,从BEV图像中提取旋转不变的特征。将BEV图像I上的旋转变换R∈SO(2)表示为R◦I,f的旋转不变性可以表示为:
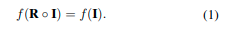
实现这种不变性的一种直接方法是使用数据增强[17]来训练网络。然而,数据增强通常需要网络具有更大的参数组来学习旋转,并且可能无法推广到训练集中未出现的旋转和场景组合。在这项工作中,我们使用组卷积网络和NetVLAD的级联来实现旋转不变性。我们的BEVPlace具有很强的泛化能力,因为该网络天生具有旋转不变性。
4.1 鸟瞰图像生成
我们遵循BVMatch [20]的方法,使用点密度来构建图像。我们将地面空间分为网格,网格大小为0.4米。对于点云m,我们计算每个网格中的点数,并使用归一化的点密度作为BEV图像I的像素强度。
4.2 组卷积网络(旋转变换)
组卷积将特征映射视为对应对称群的函数[30]。考虑2D旋转群SO(2),在BEV图像I上应用组卷积f_{gc}会产生旋转等变特征,可以写成
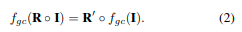
也就是说,将输入I通过旋转变换R进行变换,然后通过映射f_{gc}传递它应该与首先通过f_{gc}映射I,然后使用R’ ∈ SO(2)变换特征的结果相同。通常,设计f来使R’ = R。
组卷积已经发展了几年,有一些成熟的组卷积设计[30、18、32]。我们基于GIFT[18]实现了我们的网络。GIFT最初是为图像匹配设计的,可以产生独特的局部特征。我们对GIFT的主要修改是删除尺度特征,因为BEV图像之间没有尺度差异。我们网络实现的更多细节附在补充材料中。
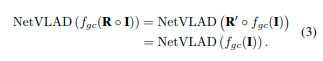
4.3 损失函数
对于基于LiDAR的地点识别问题,有一些损失函数[1、33]。在这项工作中,我们使用简单常用的懒惰三元组损失[1]来训练我们的网络,其公式为:
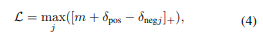
其中[…]+表示铰链损失,m是边界值,δ_{pos}是锚定点云m_a和其结构相似(“正”)点云之间的特征距离,δ_{negj}是m_a和其结构不相似(“负”)点云之间的特征距离。我们遵循[1、19、33]的训练策略,如果两个点云的几何距离小于ε米,则将它们视为结构相似的点云。
5. 位置估计
Lazy Triplet Loss损失函数强制网络学习保留几何空间中点云邻接关系的映射。虽然没有一个显式的映射函数揭示了特征空间和几何空间之间的关系,但我们观察到全局特征的距离和点云的几何距离本质上是相关的。基于这个属性,我们恢复查询和匹配之间的几何距离,然后将其用于位置估计。
5.1 特征和几何距离之间的统计相关性
为了揭示特征空间和几何空间之间的关系,我们在KITTI数据集[9]的序列“00”上训练我们的方法。然后,我们绘制了数据集不同序列中所有点云对的特征距离和几何距离。如图3所示,对于所有序列,特征距离随着几何距离的增加而近似单调地增加,并在点云彼此远离时饱和。这种现象是直观的,因为如果两个点云在几何上更接近,则它们更相似,因此特征距离更小。可以看到,由于序列在不同场景中收集,平均曲线和标准偏差在不同序列中有所不同。尽管如此,平均曲线具有相似的形状,并且可以用基于广义高斯核[23]的函数表示,该函数为:

其中,α是最大特征距离,γ和β控制曲线形状。
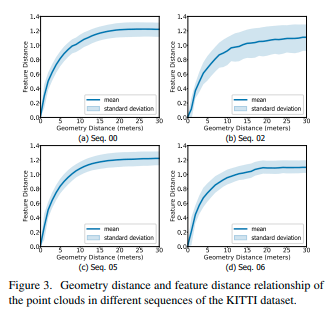
图3. KITTI数据集不同序列中点云的几何距离和特征距离关系。
5.2 映射模型
上述映射函数启发我们从特征距离恢复几何距离,并进一步估计查询点云的位置。然而,由于点云的外观变化,这种映射关系在局部区域可能略有不同。为了更准确地恢复几何距离,我们为数据库M中的每个点云m_i建立一个映射函数。具体来说,我们计算它与M中所有其他点云的特征距离和几何距离。然后,我们使用公式5拟合曲线并计算参数α_i、β_i和γ_i。完成后,我们可以根据公式5恢复查询点云m_q到m_i的几何距离。
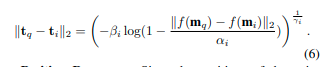
5.3 讨论
实际上,从特征距离到几何距离的映射单调性对于其他方法也适用。图4绘制了两种最先进的方法Minkloc3D-V2 [15]和OverlapTransformer [21]在KITTI数据集的序列“00”和“06”上特征空间和几何空间之间的关系。尽管这些方法的映射形状非常不同,它们都可以用具有特定参数的公式5近似描述,因此也可以基于映射模型估计位置。



评论(0)
您还未登录,请登录后发表或查看评论