

0. 简介
深度神经网络在各项任务中均展现出卓越的性能,但是它们缺乏鲁棒性、可靠性以及过于自信的倾向,这给它们在自动驾驶等安全关键应用中的部署带来挑战。在这方面,量化模型预测所固有的不确定性是解决这些缺陷的有希望的努力方向。在《U-CE: Uncertainty-aware Cross-Entropy for Semantic Segmentation》中提出了一种新型的不确定性感知交叉熵损失(U-CE),通过对交叉熵损失(CE)逐像素加权,将动态预测不确定性加入训练过程。
1. 主要贡献
本文的贡献总结如下:
- 本文提出了U-CE损失函数,其利用不确定性估计来引导优化过程,突出了具有高度不确定性的区域;
- 本文在两个基准数据集Cityscapes和ACDC上进行了大量的实验,通过两个常见的主干网络ResNet-18和ResNet-101,证明了U-CE相对于常规CE训练的优越性;
- 本文通过多次消融研究和深入讨论,提出了U-CE的额外见解、局限性和潜在改进方向。
2. 总体框架
U-CE的核心思想是将预测的不确定性纳入训练过程中,以提高分割性能。如图2所示,我们提出了两种简单但非常有效的改进方法来适应常规训练过程:
-
在训练过程中,我们使用蒙特卡洛Dropout从后验分布中进行采样,以获得与常规分割预测一起的预测不确定性。
-
我们根据收集到的不确定性对常规交叉熵损失进行像素级加权。
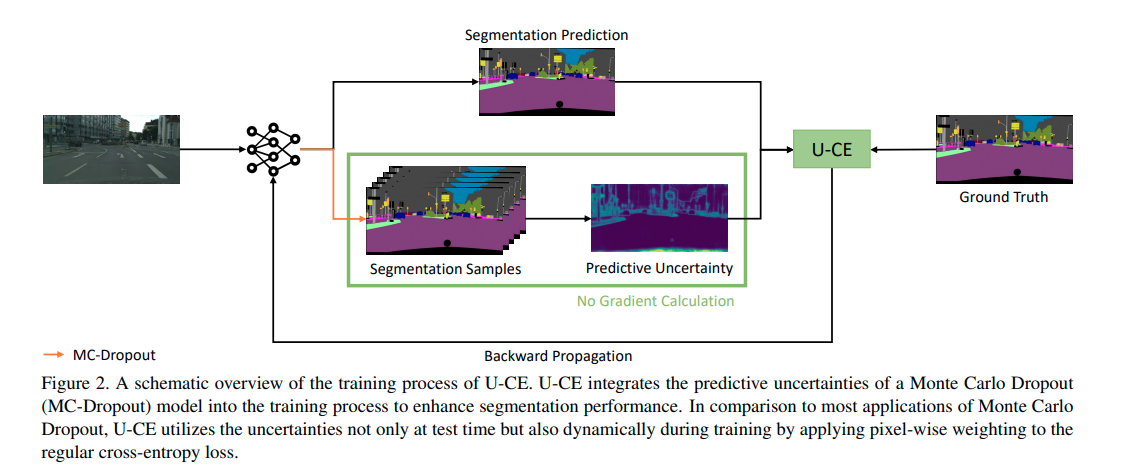
图2. U-CE训练过程的示意图。U-CE将Monte Carlo Dropout(MC-Dropout)模型的预测不确定性整合到训练过程中,以提高分割性能。与大多数Monte Carlo Dropout的应用相比,U-CE不仅在测试时利用不确定性,还通过对常规交叉熵损失进行像素级加权,在训练过程中动态地利用不确定性。
为了在训练过程中计算预测不确定性,我们选择了蒙特卡洛Dropout。它易于实现,需要最少的调整,并且在计算上比Deep Ensembles更高效。然而,值得注意的是,其他不确定性量化方法也可以用于U-CE。
3. 分割抽样
与通常使用的蒙特卡洛Dropout不同,U-CE在测试时间和训练过程中都将抽样过程从后验分布中引入。为了计算我们的不确定性感知交叉熵损失所需的不确定性,我们在每个训练步骤中执行β个抽样迭代。这会生成β个分割样本,除了常规的分割预测之外。值得注意的是,在抽样过程中禁用梯度计算,因为对于反向传播来说,这是不必要的,反向传播仅依赖于常规的分割预测。通过在抽样过程中禁用梯度计算,我们减少了U-CE在训练时间和GPU内存使用方面的额外计算开销。
3.1 不确定性感知交叉熵损失
U-CE的最终目标函数建立在众所周知的分类交叉熵损失基础上,可以定义为:
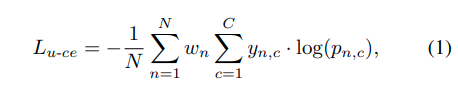
L_{u-ce}是一种对不确定性敏感的交叉熵损失函数,用于单个图像。N是图像中像素的数量,C是类别的数量,y_{n,c}是相应的真实标签,p_{n,c}是相应的预测softmax概率,w_n表示像素级的不确定性权重。值得注意的是,通过将所有像素的w_n设置为1,方程1简化为常规的交叉熵损失函数。 像素级的不确定性权重w_n可以表示为:
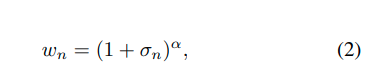
其中,σ_n表示预测的不确定性,α以指数方式控制不确定性的影响。预测的不确定性σ表示分割样本预测类别的softmax概率的标准差。 伪代码。最后,算法1展示了如何以简化的方式在训练步骤中使用UCE。如前所述,常规训练过程的两个关键调整是在训练过程中使用蒙特卡洛Dropout进行采样,并对常规交叉熵损失应用像素级的不确定性加权。


图3. 城市景观和ACDC验证集的示例图像(a),相应的真实标签(b),模型的分割预测(c),二进制准确率图(d)和预测不确定性(e)。二进制准确率图中的白色像素要么是错误的预测,要么是无效类别,在真实标签中呈黑色。对于不确定性预测,较亮的像素表示较高的预测不确定性。前三行展示了使用ResNet-18骨干网络和20%的丢弃率,在Cityscapes数据集上训练200个时期的模型的结果[8]。后三行展示了使用ResNet-101骨干网络和20%的丢弃率,在ACDC数据集上训练500个时期的模型的示例[41]。



评论(0)
您还未登录,请登录后发表或查看评论