

0. 简介
使用神经网络来匹配2D公开地图的做法是一个很有趣的方法,人们可以使用简单的2D地图在3D环境中指明自己所处的位置,而大部分视觉定位算法则依赖于昂贵的、难以构建和维护的3D点云地图。为了弥合这一差距《OrienterNet: Visual Localization in 2D Public Maps with Neural Matching》提出了第一个能够在人类经常使用的语义2D地图中进行分米级单目定位的算法OrienterNet。OrienterNet通过匹配一个图像的神经鸟瞰表示和公开的OpenSreet地图来估计输入图像的位置和朝向。OrienterNet使用相机位姿进行监督训练并以端到段的方式进行语义匹配。相关的代码已经在Github上开源了。
1. 主要贡献
本文介绍了一种全新的方法,可以在使用与人类相同的地图的情况下,以亚米级的精度定位单个图像和图像序列。这些平面地图仅编码了少数重要对象的位置和粗略的二维形状,而不包括它们的外观和高度。这种地图非常紧凑,尺寸比三维地图小104倍,因此可以存储在移动设备上,并用于大范围内的设备定位。我们使用开放街道地图(OSM)[46]展示了这些功能,这是一张公开可访问且由社区维护的世界地图,使任何人都可以免费定位任何地方。这种解决方案不需要建立和维护昂贵的三维地图,也不需要收集可能敏感的地图数据
表1. 视觉定位的地图类型。来自OpenStreetMap的平面地图由带有元数据的多边形和线条组成。它们是免费公开的,不存储敏感的外观信息,与卫星图像和使用SfM构建的3D地图相比。它们还很紧凑:可以下载并存储大面积地图到移动设备上。我们展示了它们编码了足够的几何信息以实现准确的3自由度定位。
OrienterNet学习以端到端的方式比较视觉和语义数据,仅通过相机姿态进行监督。这通过利用OSM所暴露的高多样性语义类别,从道路和建筑物到长椅和垃圾桶等对象,得出准确的姿态估计。OrienterNet还具有快速和高度可解释性。我们训练了一个单一模型,能够很好地推广到以前未见过的城市,并跨越由不同视角拍摄的各种相机图像,如车载、自行车载或头戴式、专业或消费级相机。
2. 在2D地图中定位单个图像
问题表述:在典型的定位场景中,我们的目标是估计图像在世界中的绝对6自由度姿态。在现实假设下,我们将这个问题简化为估计一个由位置(x, y) ∈ \mathbb{R}^2 和朝向角θ ∈ (−π, π]组成的3自由度姿态ξ = (x, y, θ)。 这里我们考虑一个以东-北-垂直方向对应于x-y-z轴的地心坐标系。
首先,我们可以很容易地假设我们知道重力的方向,这是人类通过内耳自然获得的信息,并且可以通过大多数设备中嵌入的惯性单元进行估计。我们还观察到我们的世界大部分是平面的,并且人和物体在室外空间中的运动大多限制在2D表面上。相机的精确高度总是可以通过局部SLAM重建中与地面的距离来估计。
输入:我们考虑一个具有已知针孔相机标定的图像I。通过使用已知重力计算的单应性矩阵对图像进行校正,使其滚动和倾斜为零,即其主轴是水平的。我们还给出了一个粗略的位置先验ξ_{prior}。这可以是一个噪声较大的GPS位置或先前的定位估计,并且可能偏离20米以上。这对于像城市峡谷这样的多路径环境中的消费级传感器来说是一个现实的假设。 地图数据是从OSM查询的,以ξ_{prior}为中心的正方形区域,其大小取决于先验的噪声程度。数据由一系列多边形、线和点组成,每个都有给定的语义类别,并且其坐标以相同的局部参考框架给出。
概述 - 图2:OrienterNet由三个模块组成:1)图像CNN从图像中提取语义特征,并通过推断场景的3D结构将其转换为正交鸟瞰图(BEV)表示T。2)地图CNN将OSM地图编码为嵌入语义和几何信息的神经地图F。3)我们通过将BEV与地图进行穷举匹配来估计相机姿态ξ 的概率分布。
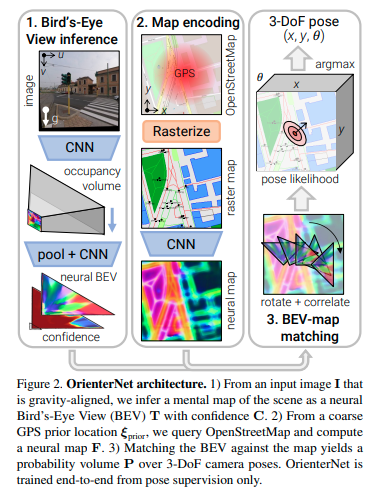
2.1 神经鸟瞰视图推理
概述:从一张单独的图像I中,我们推断出一个分布在与相机视锥对齐的L×D 网格上的BEV表示T ∈ \mathbb{R}^{L×D×N},由N维特征组成。网格上的每个特征都被赋予一个置信度,得到一个矩阵C ∈ [0, 1]^{L×D}。这个BEV类似于人们在俯视地图中自我定位时从环境中推断出的心理地图[37, 45]。
图像和地图之间的跨模态匹配需要从视觉线索中提取语义信息。已经证明,单眼深度估计可以依赖于语义线索[3],而且这两个任务之间存在有益的协同作用[29, 34]。因此,我们依靠单眼推理将语义特征提升到BEV空间。在处理语义任务的过去工作[49, 52, 55]的基础上,我们通过两个步骤获得神经BEV:i) 将图像特征转换为极坐标表示,将图像列映射到极射线上,ii) 将极坐标网格重新采样为笛卡尔网格(图3)。
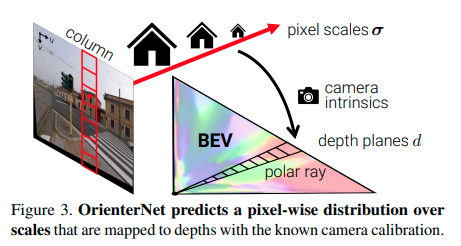
图3. OrienterNet根据已知的相机标定,预测出一个像素级别的尺度分布,并将其映射到深度上。
极坐标表示:首先,CNN Φ_{image}从图像中提取一个U×V特征图X ∈ \mathbb{R}^{U×V ×N}。我们考虑在相机前方采样了D个深度平面,采样间隔为∆,即具有值{i · ∆|i ∈ {1 . . . D}}。由于图像与重力对齐,X中的每个U列对应于3D空间中的一个垂直平面。因此,我们将每个列映射到U×D极坐标表示\tilde{X} ∈ \mathbb{R}^{U×D×N}中的一条射线上。为此,我们对于每个极坐标单元(u, d),预测一个概率分布α_{u,d} ∈ [0, 1]^V,表示对应图像列中的像素。

与直接回归深度分布α不同,我们回归一个与相机标定参数无关的尺度分布S。尺度是指物体在三维世界和图像中的大小比例[3],等于焦距f与深度的比值。我们考虑一组以对数分布的尺度。

Φ_{image}还预测了每个像素点(u, v)的得分向量S_{u,v} ∈ \mathbb{R}^S,其中的元素对应于尺度区间σ。然后,我们得到了每个深度区间d的分布α_{u,d}。
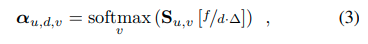
其中[·]表示线性插值。
这个公式等价于一个注意力机制,将极坐标射线映射到图像列,并将得分从线性深度重新采样到对数尺度。当尺度模糊且难以推断时,视觉特征会在射线上分布在多个深度上,但仍然为良好定位的地图点提供几何约束[35]。针对驾驶场景的研究[49, 52, 55]考虑由相同型号相机捕获的数据集,并直接回归α。因此,他们在网络权重中编码了焦距,学习了从物体尺度到深度的映射。与之不同的是,我们的公式可以在测试时适用于任意相机,假设焦距是系统的输入。
BEV网格:我们通过沿着横向方向进行线性插值,将极坐标特征映射到大小为L×D的笛卡尔网格,其中U个极坐标射线映射到间隔为∆的L个列。然后,由一个小型CNN Φ_{BEV}处理生成的特征网格,输出神经BEV T和置信度C。
2.2 神经地图编码 (重点内容)
我们将平面地图编码为一个W×H的神经地图F ∈ \mathbb{R}^{W×H×N},结合了几何和语义信息。
地图数据:根据语义类别的不同,OpenStreetMap元素被定义为多边形区域、多段线或单个点。区域的例子包括建筑物轮廓、草坪、停车场;线段包括道路或人行道中心线、建筑物轮廓;点包括树木、公交车站、商店等。附录B.1列出了所有类别。这些元素的准确定位提供了定位所需的几何约束,而它们丰富的语义多样性有助于消除不同姿态的歧义。
预处理:我们首先将区域、线段和点作为一个3通道图像进行栅格化,采用固定的地面采样距离∆,例如50厘米/像素。这种表示比以前的工作中对人类可读的OSM瓦片进行简单栅格化更具信息量和准确性[56, 80]。
编码:我们将每个类别与一个N维嵌入相关联,通过学习得到一个W×H×3N的特征图。然后,通过CNN Φ_{map}将其编码为神经地图F,提取用于定位的几何特征。F没有进行归一化,我们让Φ_{map}调节其范数作为匹配中的重要性权重。图4中的示例显示,F通常看起来像一个距离场,我们可以清晰地识别出建筑物的角落或相邻边界等显著特征。 Φ_{map}还预测了地图每个单元格的一元位置先验Ω ∈ \mathbb{R}^{W×H}。该分数反映了在每个位置拍摄图像的可能性。我们很少期望在河流或建筑物中拍摄图像。

图4. 我们训练了一个能够在许多数据集上具有良好泛化能力的单一模型。OrienterNet能够处理不同的摄像头、街道级别的视角以及未知的城市,因此适用于增强现实和机器人技术。在输入地图上叠加的单张图像预测(黑色箭头)与真实值(红色箭头)非常接近,并且比嘈杂的GPS定位(蓝色点•)更准确。该模型有效地利用了建筑物的角落和边界、人行横道、人行道、道路交叉口、树木和其他常见的城市物体。在具有重复元素的场景中,可能性地图可以是多模态的(最后两行)-我们将局部最大值处的预测方向表示为小箭头。
2.3 模板匹配姿态估计 (重点内容)
概率体积:我们对相机姿态ξ进行离散概率分布的估计。这种估计是可解释的,并完全捕捉了估计的不确定性。因此,在模糊的情况下,分布是多峰的。图4显示了各种示例。这使得将姿态估计与GPS等其他传感器融合变得容易。计算这个体积是可行的,因为姿态空间已经被减少到3个维度。它被离散化为每个地图位置和在正常间隔内采样的K个旋转。 这产生了一个W×H×K的概率体积P,使得 P(ξ|I, map, ξ_{prior}) = P[ξ]。它是图像-地图匹配项M和位置先验Ω的组合:
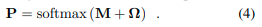
M和Ω代表图像条件和图像独立的非归一化对数得分。Ω沿着旋转维度进行广播,softmax函数对概率分布进行归一化。
图像-地图匹配:通过穷举匹配神经地图F和BEV T,得到一个得分体积M。每个元素通过将F与相应姿态变换的T进行相关计算得到。
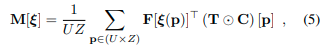
其中,ξ(p)将2D点p从BEV转换到地图坐标系。置信度C用于遮罩掉与BEV空间的某些部分无关的区域,例如被遮挡的区域。这个公式的好处是通过在傅里叶域中进行批量乘法,将旋转T K次和执行单个卷积的操作高效实现[7, 8]。
姿态推断:我们通过最大似然估计一个单一的姿态:ξ^∗ = argmax_ξ P(ξ|I, map, ξ_{prior})。当分布主要是单峰的时候,我们可以通过P在ξ^∗周围的协方差来获得不确定性的度量。
3. 序列和多摄像头定位
在具有少量独特语义元素或重复模式的位置中,单张图像的定位是模糊的。当相对姿态已知时,可以通过在多个视角上积累额外线索来消除这种挑战。这些视角可以是具有VI SLAM姿态的图像序列,也可以是来自校准的多摄像头设备的同时视角。图5展示了通过随时间累积预测来消除这种困难情景的示例。不同的帧在不同方向上约束姿态,例如在交叉口之前和之后。融合更长的序列可以获得更高的准确性(图6)。
让我们用ξ_i表示视角i的未知绝对姿态,用\hat{ξ}_{ij}表示从视角j到i的已知相对姿态。对于任意参考视角i,我们将所有单视图预测的联合似然表示为
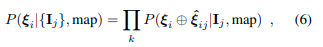
其中⊕表示姿态合成运算符。这可以通过将每个概率体积P_j变形到参考帧i来高效计算。我们还可以通过迭代变形和归一化来定位连续流中的每个图像,就像经典的马尔可夫定位[11, 66]中那样。



评论(0)
您还未登录,请登录后发表或查看评论